Benchmarks
Dmitriy Selivanov
18 March, 2025
Source:vignettes/benchmarks/Benchmarks.Rmd
Benchmarks.Rmd*All benchmarks below are done on a pretty old Intel Xeon X3470 CPU with 4 cores, 8 threads @ 2.93GHz . You can expect ~2x better performance on modern CPUs.
There are many tools to benchmark HTTP API. We will use apib which is successor of a
standard ab tool.
We will benchmark a very simple web service - it receives HTTP
request at /fib?n=10 and answers with fibonacci number.
Details and methodology
Our testing RestRserve application is implemented below:
calc_fib = function(n) {
if (n < 0L) stop("n should be >= 0")
if (n == 0L) return(0L)
if (n == 1L || n == 2L) return(1L)
x = rep(1L, n)
for (i in 3L:n) x[[i]] = x[[i - 1]] + x[[i - 2]]
x[[n]]
}
bench_app = function(calc_fn) {
library(RestRserve)
backend = BackendRserve$new()
app = Application$new(content_type = "text/plain")
app$logger$set_log_level("off")
app$add_get("/fib", FUN = function(request, response) {
n = as.integer(request$get_param_query("n"))
if (length(n) == 0L || is.na(n)) {
raise(HTTPError$bad_request())
}
response$set_body(list(answer = calc_fn(n)))
})
backend$start(app = app, http_port = 8080)
}Sample calc_fib() benchmarking:
microbenchmark::microbenchmark(low = calc_fib(10), times = 10)
#> Warning in microbenchmark::microbenchmark(low = calc_fib(10), times = 10): less
#> accurate nanosecond times to avoid potential integer overflows
#> Unit: nanoseconds
#> expr min lq mean median uq max neval
#> low 861 861 867412.4 902 984 8665473 10Benchmarking Rserve backend
At the moment RestRserve supports single backend - Rserve.
Configurations:
-
RestRservecan utilize all CPU cores and process requests in parallel. We will use multiple number of threads to see how it affects performance. - During application
RestRservechecksRESTRSERVE_RUNTIME_ASSERTSenvironment variable. It controls the amount of input validationRestRserveperforms internally using checkmate package. Despite the fact that runtime checks comes with additional time overhead this variable is set toTRUEby default. We value correctness and robustness of the application at the first place. We will benchmark application with different values ofRESTRSERVE_RUNTIME_ASSERTSto see the difference.
Code below implements allows to test combinations options:
library(callr)
library(data.table)
parse_apib_results = function(x) {
apib_executable_path = "apib"
#apib_executable_path = path.expand("~/projects/apib/release/apib/apib")
csv_header = system2(command = apib_executable_path,
args = "--header-line", stdout = T)
csv_header = strsplit(csv_header, ",", T)[[1]]
csv_header = c("n_threads", "fibonacci", "flavor", csv_header[-1])
if (length(x) == 1) x = paste0(x, "\n")
results = paste(x, collapse = "\n")
fread(results, col.names = csv_header)
}
run_apib = function(
n_threads = c(4, 2, 1),
n_sec = 5,
keep_alive = -1,
flavor = "",
fib_count = 10) {
apib_executable_path = "apib"
#apib_executable_path = path.expand("~/projects/apib/release/apib/apib")
results = character()
for (n_thread in n_threads) {
res = system2(
command = apib_executable_path,
args = sprintf(
"-c %d -d %d -k %d --csv-output \'http://127.0.0.1:8080/fib?n=%d\'",
n_thread, n_sec, keep_alive, fib_count
),
stdout = TRUE
)
results[[length(results) + 1]] = paste0(n_thread, ",", fib_count, ",", flavor, res)
}
results
}
apib_bench = function(
n_sec = 5,
keep_alive = -1,
fib_counts = 10,
runtime_checks = c(FALSE, TRUE)) {
results = character()
for (fib_count in fib_counts) {
for (runtime_check in runtime_checks) {
rr = r_bg(
bench_app,
list(calc_fn = calc_fib),
env = c("RESTRSERVE_RUNTIME_ASSERTS" = as.character(runtime_check))
)
# Wait for R to start
Sys.sleep(2)
flavor = if (runtime_check) "RestRserve + runtime checks" else "RestRserve"
results = c(
results,
run_apib(
n_sec = n_sec,
keep_alive = keep_alive,
flavor = flavor,
fib_count = fib_count
)
)
cat(sep = "",
"fibonacci: ", fib_count, "; flavor: ", flavor, "\n",
paste0(rr$read_output(), collapse = "\n"), "\n"
)
rr$kill_tree()
}
}
parse_apib_results(results)
}
results_runtime = apib_bench(keep_alive = -1, fib_counts = 10)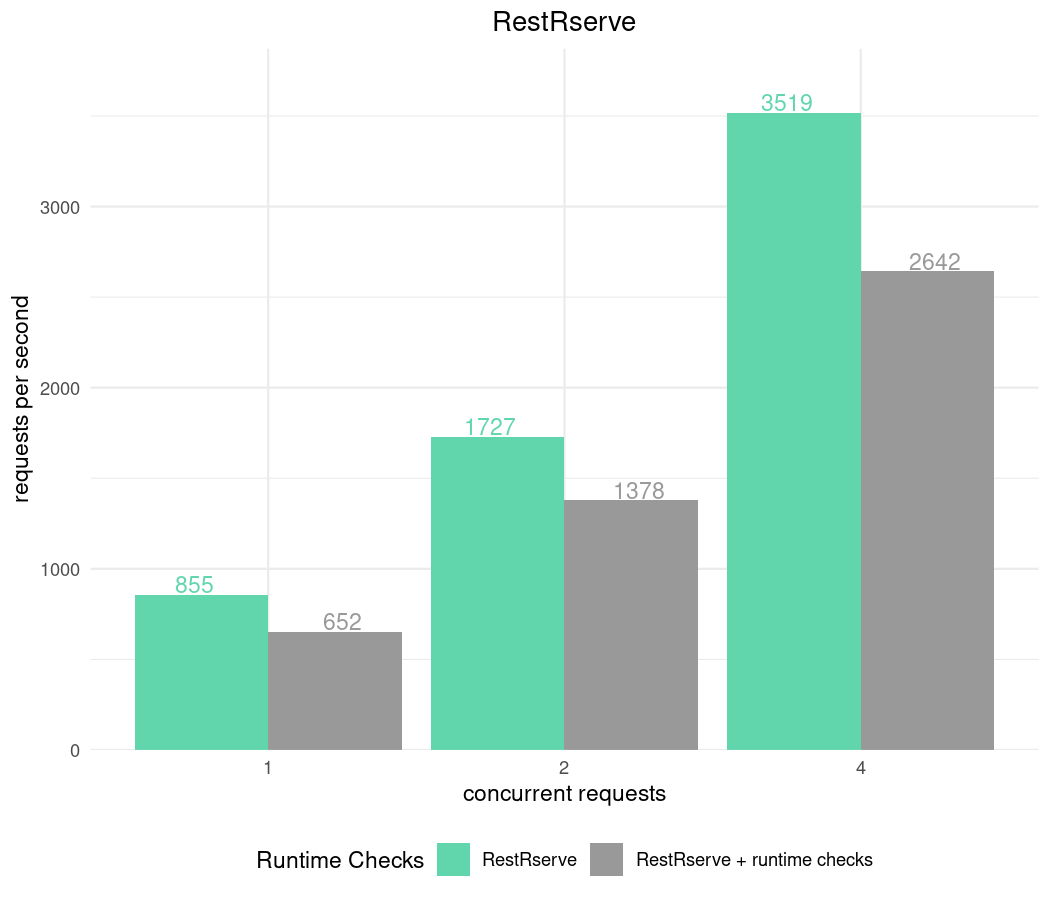
No keep-alive
Keep in mind that creating new connections is quite expensive for any
HTTP server. For RestRserve’s Rserve backend
this is particularly true since for each new connection it forks a child
process (which has relatively high cost). With other backends slow down
might be less significant.
results_no_keep_alive = apib_bench(keep_alive = 0, fib_counts = 10)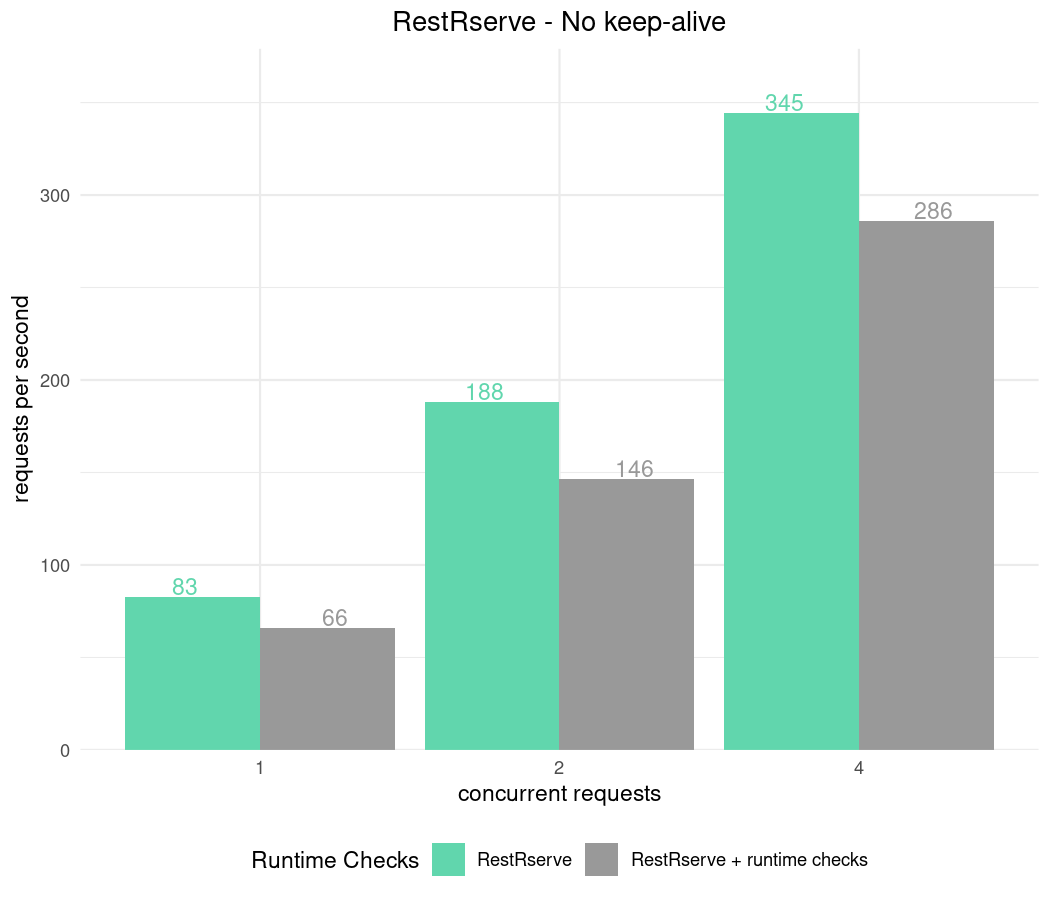
Nonetheless one can always put application behind proxy (such as HAproxy or nginx). It will maintain pool of connections to RestRserve and hence won’t suffer from creating new connections.
Comparison with Plumber
Support for promises and
future
was added in plumber
v1.0.0. Extra coding will need to be done within a plumber definition to
distinguish which routes utilize promises.
We will rewrite our calc_fib function in a less
efficient way in order to simulate different amount of computation
required by handler. We will benchmark frameworks against three styles
of routes (low computation, n = 15; medium computation,
n = 20; high computation, n = 25) using
multiple apib testing threads (1, 2, 4).
calc_fib = function(n) {
calc_fib_rec = function(n) {
if (n < 0L) stop("n should be >= 0")
if (n == 0L) return(0L)
if (n == 1L || n == 2L) return(1L)
x = rep(1L, n)
for (i in 3L:n) x[[i]] = x[[i - 1]] + x[[i - 2]]
x[[n]]
calc_fib_rec(n - 1) + calc_fib_rec(n - 2)
}
calc_fib_rec(n)
}
microbenchmark::microbenchmark(
low = calc_fib(15),
medium = calc_fib(20),
high = calc_fib(25), times = 10
)
#> Unit: microseconds
#> expr min lq mean median uq max neval
#> low 512.213 519.060 649.7557 521.3765 531.893 1793.955 10
#> medium 5721.673 5788.052 5952.9622 5861.8725 5876.325 7086.276 10
#> high 67033.606 67107.898 68340.5589 67599.7955 68404.482 74794.578 10
plumber_app = function(calc_fn, use_future = FALSE) {
if (isTRUE(use_future)) {
# multiple cores
library(future)
plan(multiprocess(workers = 4)) # max number of threads
fib_route = function(n = -1) {
n = as.integer(n)
if (is.na(n)) stop("\"n\"must be integer number.")
future({
calc_fn(n)
})
}
} else {
# single core
fib_route = function(n = -1) {
n = as.integer(n)
if (is.na(n)) stop("\"n\"must be integer number.")
calc_fn(n)
}
}
library(plumber)
pr() %>%
pr_get(
"/fib",
fib_route,
serializer = plumber::serializer_text()
) %>%
pr_run(port = 8080)
}
apib_bench_plumber = function(
n_sec = 5,
keep_alive = -1,
fib_counts = c(15, 20, 25)) {
results = character()
for (fib_count in fib_counts) {
for (use_future in list(TRUE, FALSE)) {
rr = r_bg(
plumber_app,
list(calc_fn = calc_fib, use_future = use_future),
stdout = "|", stderr = "2>&1"
)
Sys.sleep(2)
flavor = if (use_future) "plumber + future" else "plumber"
results = c(
results,
run_apib(
n_threads = c(4, 2, 1),
n_sec = n_sec,
keep_alive = keep_alive,
flavor = flavor,
fib_count = fib_count
)
)
cat(sep = "",
"fibonacci: ", fib_count, "; flavor: ", flavor, "\n",
paste0(rr$read_output(), collapse = "\n"), "\n"
)
rr$kill_tree()
}
}
parse_apib_results(results)
}
N_SEC = 10
results_restrserve = apib_bench(fib_counts = c(15, 20, 25), keep_alive = -1,
runtime_checks = FALSE, n_sec = N_SEC)
results_plumber = apib_bench_plumber(fib_counts = c(15, 20, 25), keep_alive = -1, n_sec = N_SEC)
results_compare = rbindlist(list(results_plumber, results_restrserve))Results

As can be seen RestRserce performs very well on every
workload and scales linearly with number of cores.
keep-alive disabled
Additionally we may explore environments where web-service exposed
directly to many clients without having load balancer or proxy behind
it. This is not very common across real-world deployments, but still
worth to keep in mind. We can be simulate such scenario by setting
keep_alive = 0:
results_restrserve = apib_bench(fib_counts = c(15, 20, 25), keep_alive = 0,
runtime_checks = FALSE, n_sec = N_SEC)
results_plumber = apib_bench_plumber(fib_counts = c(15, 20, 25), keep_alive = 0, n_sec = N_SEC)
results_compare = rbindlist(list(results_plumber, results_restrserve))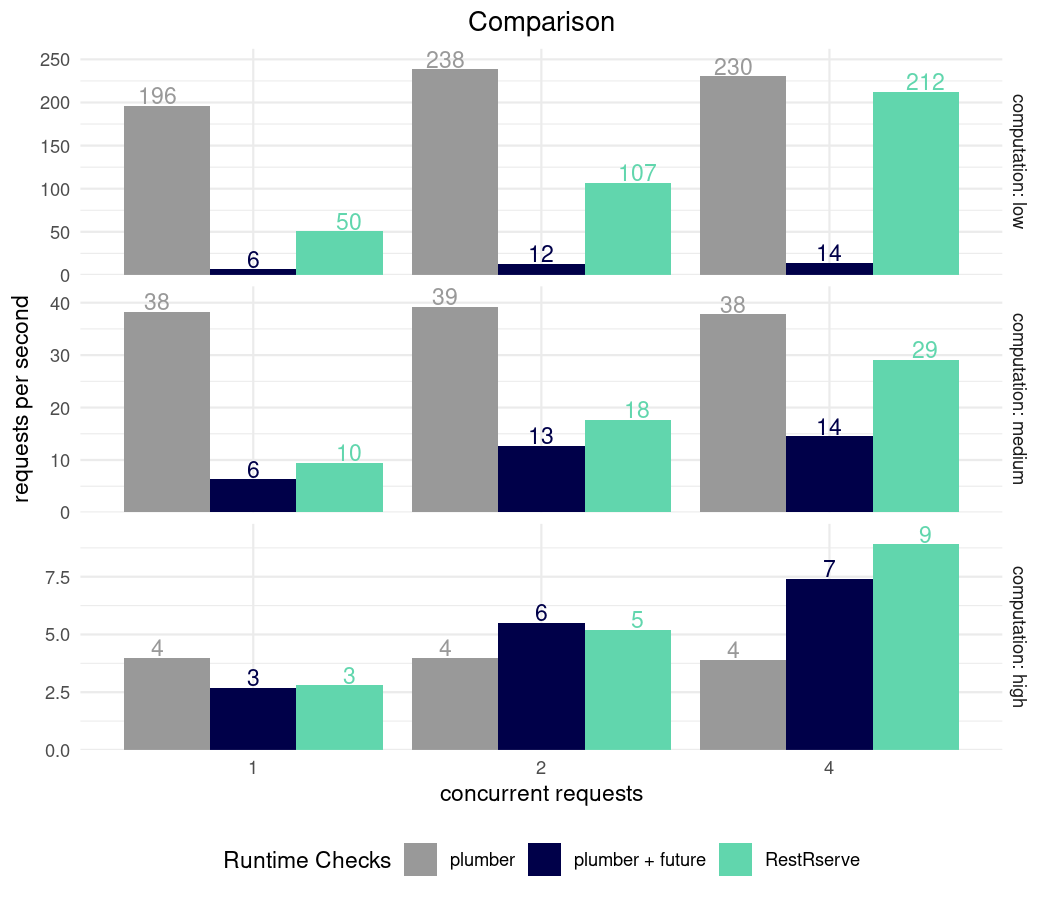
Due to the overhead of creating a new process for each request and R’s byte compiler
overhead RestRserve with Rserve backend
does not perform as quickly as plumber when computing
instantaneous routes. However, RestRserve still shows it’s
strength when executing routes that have high computational costs. No
extra coding logic is needed to leverage RestRserve’s
multi-threaded execution. Mixing plumber and
future together for high computation routes brings
performance that scales with the number of concurrent requests, but at
the cost of extra route logic and domain knowledge.